08 Apr 2024
Introduction
Telemetry is a core aspect of monitoring and observability; it helps making sure systems run smoothly, troubleshooting issues after the fact, or being alerted when things go pear-shaped.
Losing telemetry seriously hinders those capabilities and it is what happened to me on my most recent project.
I was lucky enough to discover it soon after it happened, completely by accident!
In this post, we’ll go through how OpenTelemetry instrumentation works in Node.js, how we lost critical telemetry in our project, and how we made sure it won’t happen again.
OpenTelemetry instrumentation in Node.js
If you’re new to OpenTelemetry, here’s an excerpt from the official documentation:
OpenTelemetry is an Observability framework and toolkit designed to create and manage telemetry data such as traces, metrics, and logs.
Instrumentation is the act of adding observability code to an application.
When you develop an app, you might use third-party libraries and frameworks to accelerate your work.
If you then instrument your app using OpenTelemetry, you might want to avoid spending additional time to manually add traces, logs, and metrics to the third-party libraries and frameworks you use. (source).
Most applications use third-party libraries for the building blocks of an application, like the HTTP server, making database queries, issuing outgoing HTTP requests, etc and in my experience, most of these libraries don’t have native support for OpenTelemetry, so we rely on specific instrumentation libraries that patch the instrumented libraries at runtime to emit telemetry when certain events occur.
How we lost telemetry in our project
We updated npm packages 😇.
Because instrumented libraries are patched at runtime by instrumentation libraries, there needs to be some contract between the two to ensure that the functionality of instrumented libraries is not affected. This is typically done with instrumentation libraries declaring a supported version range for the package they instrument.
Our project is a Node.js app that integrates with a SQL Server database using the mssql npm package, which uses tedious as a low-level TDS implementation.
In order to get telemetry around our database queries, we installed the @opentelemetry/instrumentation-tedious instrumentation package.
All was fine until we decided to update the npm packages; a new major version of mssql had been released, itself bringing a new version of tedious.
The release notes didn’t mention breaking changes, and it all seemed to work fine during testing.
I later realised, by accident, that our database queries were not instrumented anymore.
What happened is that the new version of tedious we installed, v16, was outside of the supported version range of the associated instrumentation package, which at the time of writing only supports versions up to v15.
How we fixed the situation
We found a report indicating that the instrumentation is compatible with tedious v16, so we patched the instrumentation with patch-package to amend the supported version range.
The next step was to ensure we would be notified the next time we find ourselves in this situation.
Unfortunately, the OpenTelemetry SDK doesn’t emit specific events or log entries when an instrumentation is found to not be compatible with the instrumented package, so we came up with a test that leverages the instrumentations init function that includes the name of the package they instrument, and the version range they support.
import type { InstrumentationNodeModuleDefinition } from '@opentelemetry/instrumentation/build/src/instrumentationNodeModuleDefinition'
import path from 'node:path'
import semver from 'semver'
import fs from 'node:fs'
import { instrumentations } from './instrumentations'
import os from 'node:os'
import { groupBy } from 'lodash'
describe('OpenTelemetry instrumentations', () => {
it(`are compatible with the installed version of the packages they instrument`, () => {
const applicableInstrumentationDefinitions = instrumentations
// They can expose several module definitions; redis does: one for @redis/client, one for @node-redis/client
.flatMap((x) => (x as any).init() as InstrumentationNodeModuleDefinition<unknown> | InstrumentationNodeModuleDefinition<unknown>[])
// Only get the ones that apply to us
.filter(({ name }) => fs.existsSync(getPackageNodeModulesDirectory(name)))
const groupedByPackageName = groupBy(applicableInstrumentationDefinitions, (x) => x.name)
const results = Object.entries(groupedByPackageName).map(([packageName, instrumentationDefinitions]) => {
const installedVersion = getPackageVersion(packageName)
const incompatibleInstrumentationDefinitions = instrumentationDefinitions.filter(({ supportedVersions }) => {
// http and https instrumentations have a '*' version range, so we special case it
// because we can't get versions for these built-in modules
if (supportedVersions.includes('*')) {
return false
}
return supportedVersions.every((x) => !semver.satisfies(installedVersion, x))
})
// If none of the definitions for a package are applicable, then we have an issue
return incompatibleInstrumentationDefinitions.length !== instrumentationDefinitions.length
? ({ result: 'success' } as const)
: ({
result: 'failure',
packageName,
packageVersion: installedVersion,
supportedVersions: incompatibleInstrumentationDefinitions.flatMap((x) => x.supportedVersions),
} as const)
})
const failures = results.filter((x): x is typeof x & { result: 'failure' } => x.result === 'failure')
if (failures.length > 0) {
throw new Error(`Some instrumentations are not compatible with the version of the installed packages:
${failures
.map(
({ packageName, packageVersion, supportedVersions }) =>
`- ${packageName}@${packageVersion}, supported versions are ${supportedVersions.join(', ')}`,
)
.join(os.EOL)}`)
}
})
})
function getPackageVersion(packageName: string): string {
// eslint-disable-next-line @typescript-eslint/no-var-requires
return require(path.join(getPackageNodeModulesDirectory(packageName), 'package.json')).version
}
function getPackageNodeModulesDirectory(packageName: string): string {
return path.join(process.cwd(), 'node_modules', packageName)
}
A few notes about this:
- This assumes that the instrumentations you’re configuring in your application are defined in a separate file.
- Instrumentations can define several instrumentation definitions, like the Redis instrumentation exposes definitions for different modules, so we only select the ones that apply to us; the current naive check is to verify whether a matching directory exists under
node_modules.
- The winston instrumentation exposes different definitions for different version ranges, so we group the definitions by package name, and consider an instrumentation incompatible if none of the definitions satisfy the currently installed package version.
- Finally, the HTTP instrumentation and HTTPS instrumentation use
* as the supported version range; given these are built-in modules, we can’t get their installed version, so we special-case * to return early.
We may very well run into different edge cases that we will need to handle, and I’m hopeful that when this happens the test will fail with a runtime error rather than pass silently.
Conclusion
In this post, we first saw what OpenTelemetry is and how instrumentation works in Node.js.
Instrumentation libraries are so very helpful, and help you get set up with telemetry in no time.
We then discussed how instrumentations define version ranges for the package they instrument to ensure compatibility.
It’s a great concept, but in our case it means we lost instrumentation for database queries without realising it.
Finally, we went over how we fixed the issue, and the remediation step we took to minimise the risk of it happening again in the future with a test that compares the instrumentations supported version range with the versions of the packages we have installed in our project.
23 Jul 2021
Introduction
I blogged in the past about connecting to Azure SQL using AAD authentication.
By using Azure managed identity, our application can connect to Azure SQL without the need to secure any kind of credential.
However, so far it was the responsibility of the application to acquire an access token from AAD and attach it to the SQL connection.
On top of that, token caching and renewal was another aspect application developers needed to keep in mind to avoid unnecessary network requests.
Even though .NET libraries helped achieving this, it was custom code that needed to be maintained.
Let’s have a look at a new, code-free way of achieving the same result.
Native support in Microsoft.Data.SqlClient
In June 2021, Microsoft released version 3.0 of Microsoft.Data.SqlClient, the official SQL Server driver for .NET.
This release supports more scenarios around AAD authentication as it now leverages Azure.Identity.
What this means is that instead of having custom code to acquire tokens, cache them, and renew them, these operations are now handled internally by the driver.
Consumers can configure which underlying Azure.Identity credential is used through the connection string, via the Authentication keyword.
Authentication keyword value |
Underlying Azure.Identity credential used |
Typical scenario |
Sources |
| Active Directory Managed Identity |
ManagedIdentityCredential |
App running on Azure |
Managed identity |
| Active Directory Default |
DefaultAzureCredential |
Local development |
Environment variables, managed identity, VS Code, Visual Studio, Azure CLI |
Leveraging AAD authentication could not get any simpler!
public async Task Main(string[] args)
{
var connectionString = "Data Source=<my-azure-sql-instance>.database.windows.net; Initial Catalog=<my-database>; Authentication=Active Directory Default";
for (var i = 0; i < 10; i++)
{
await using var connection = new SqlConnection(connectionString);
var count = await connection.QuerySingleAsync<int>("SELECT COUNT(0) FROM [dbo].[MyTable]");
Console.WriteLine($"There are {count} items in the table");
}
}
Silly example, I know 😇.
The point is that by running this program, a single token will be acquired during the first query, and the nine others will use the token cached internally.
Potential drawbacks
I find this solution fantastic, and I’ve been using it in a couple of applications with no issues.
However, I think it’s worth mentioning that it’s not perfect, and you might want to analyse whether it’s the right approach for you.
The first effect of using this method is that since the driver orchestrates Azure.Identity itself, we lose some flexibility.
It’s not possible anymore for an application to specify a specific list of credentials via ChainedTokenCredential.
I personally don’t think this is a big issue, but some applications might have stricter requirements.
The second thing to be aware of is that since v3 is a new major version, it’s coming with breaking changes.
One of them is for columns that are mapped to properties of type byte[], if the column value is NULL, the driver will return DBNull.Value instead of an empty byte array.
This change might impact EF Core as there’s been a report of applications breaking after updating to Microsoft.Data.SqlClient v3.0, see https://github.com/dotnet/efcore/issues/25074.
At the time of writing, the EF Core team plans on fixing this for the 6.0 release, but will potentially issue a patch if it’s not too tricky to fix.
Conclusion
In this post, we saw how we can free our applications of several token-related concerns by leveraging the new supported scenarios around AAD authentication in Microsoft.Data.SqlClient.
We also emphasised that a proper analysis should be conducted before jumping on this new version as we lose some flexibility, and some breaking changes might cause issues.
Additional links:
14 Dec 2020
Introduction
Swashbuckle is a fantastic .NET library that enables developers to generate Swagger- and OpenAPI-compliant documentation for their APIs.
It also bundles swagger-ui, a tool that allows developers and API consumers to visualise the definition of an API by using the generated JSON OpenAPI document.
Unfortunately, out of the box, swagger-ui uses inline <script> and <style> tags, which are considered insecure as they can allow attackers to run arbitrary code in an application through a cross-site scripting (XSS) vulnerability.
See this Google article for more information: https://developers.google.com/web/fundamentals/security/csp/#inline_code_is_considered_harmful
Let’s see how we can work around this issue and keep a strict content security policy that disallows inline tags in our application.
As a note, this post uses the fantastic NetEscapades.AspNetCore.SecurityHeaders NuGet package developed by Andrew Lock.
It offers a strongly-typed API to work with security-related headers, CSP being one of them.
Check it out at https://github.com/andrewlock/NetEscapades.AspNetCore.SecurityHeaders.
The index.html file
The main page for swagger-ui is driven by the index.html file and its CSS and JavaScript resources.
Swashbuckle exposes configuration options for swagger-ui.
Developers can leverage that capability to change the content of the file from one application to another, or simply from one environment to another.
To support this, Swashbuckle maintain their own copy of the index.html file, in which we can find tokens that get replaced at runtime.
See the several %(<property-name>) tokens on GitHub: https://github.com/domaindrivendev/Swashbuckle.AspNetCore/blob/98a7dfe0f7ca2aa66c6daa029c3987490bd1eb20/src/Swashbuckle.AspNetCore.SwaggerUI/index.html.
From a CSP perspective, the first two issues are the inline <script> tag and both the inline <script> tags.
To remediate those, CSP offers two options:
- Allowing the hashes of the contents of the inline
<script> and <style> tags (see https://scotthelme.co.uk/csp-cheat-sheet/#hashes); or
- Specifying a
nonce attribute on the inline tags while allowing it in the content security policy; for obvious reasons, the allowed nonce must be randomly generated and change for every single HTTP request (see https://scotthelme.co.uk/csp-cheat-sheet/#nonces).
Using hashes isn’t viable here as the second inline <script> tag will contain the JSON representation of our configuration, which could change for each environment we’ll deploy to.
Different values would generate different hashes, all of which we would need to allow in our CSP.
Yuck 😧.
The solution lies in using nonces!
Swashbuckle has an extensibility point which allows to modify the contents of the index.html file that will be served.
This is done though the SwaggerUIOptions.IndexStream property.
See https://github.com/domaindrivendev/Swashbuckle.AspNetCore#customize-indexhtml.
The default value is to read the index.html file embedded in the assembly:
public class SwaggerUIOptions
{
[...]
// See https://github.com/domaindrivendev/Swashbuckle.AspNetCore/blob/89a78db9300a6c3e0854a95ecfc317c9f87c3a8c/src/Swashbuckle.AspNetCore.SwaggerUI/SwaggerUIOptions.cs#L17-L21
public Func<Stream> IndexStream { get; set; } = () => typeof(SwaggerUIOptions).GetTypeInfo().Assembly
.GetManifestResourceStream("Swashbuckle.AspNetCore.SwaggerUI.index.html");
[...]
}
Instead of sending a completely different index.html file, we’ll override this property to modify the contents dynamically for each HTTP request:
// Startup.cs
public void ConfigureServices()
{
// 1. Register IHttpContextAccessor as we use it below
services.AddHttpContextAccessor();
services
.AddOptions<SwaggerUIOptions>()
.Configure<IHttpContextAccessor>((swaggerUiOptions, httpContextAccessor) =>
{
// 2. Take a reference of the original Stream factory which reads from Swashbuckle's embedded resources
var originalIndexStreamFactory = options.IndexStream;
// 3. Override the Stream factory
options.IndexStream = () =>
{
// 4. Read the original index.html file
using var originalStream = originalIndexStreamFactory();
using var originalStreamReader = new StreamReader(originalStream);
var originalIndexHtmlContents = originalStreamReader.ReadToEnd();
// 5. Get the request-specific nonce generated by NetEscapades.AspNetCore.SecurityHeaders
var requestSpecificNonce = httpContextAccessor.HttpContext.GetNonce();
// 6. Replace inline `<script>` and `<style>` tags by adding a `nonce` attribute to them
var nonceEnabledIndexHtmlContents = originalIndexHtmlContents
.Replace("<script>", $"<script nonce=\"{requestSpecificNonce}\">", StringComparison.OrdinalIgnoreCase)
.Replace("<style>", $"<style nonce=\"{requestSpecificNonce}\">", StringComparison.OrdinalIgnoreCase);
// 7. Return a new Stream that contains our modified contents
return new MemoryStream(Encoding.UTF8.GetBytes(nonceEnabledIndexHtmlContents));
};
});
}
The remaining configuration is done in the Configure method, to allow nonces for styles and scripts in our CSP:
public void Configure()
{
// Note this sample only focuses on CSP, but you might want to set other security-related headers if you use this library
app.UseSecurityHeaders(policyCollection =>
{
policyCollection.AddContentSecurityPolicy(csp =>
{
// Only allow loading resources from this app by default
csp.AddDefaultSrc().Self();
csp.AddStyleSrc()
.Self()
// Allow nonce-enabled <style> tags
.WithNonce();
csp.AddScriptSrc()
.Self()
// Allow nonce-enabled <script> tags
.WithNonce();
[...]
});
});
}
If we access our swagger-ui page again, everything seems to be working fine! 🎉
If we refresh the page and analyse the HTML code, we can see that the value of nonce attributes added to the <script> and <style> tags changes on every request.
If we open our browser developer tools, the console should show two errors related to loading images through the data protocol.
Because this protocol is not allowed in our content security policy, the browser refuses to load them.
From what I can see, they’re related to the Swagger logo in the top-left corner and the down-facing arrow in the definition dropdown in the top-right corner.
As I believe the rest is working fine, I’ll let you decide whether you want to allow loading images from data, which is considered insecure.
If you decide to go ahead, you can use the code below:
public void Configure()
{
app.UseSecurityHeaders(policyCollection =>
{
policyCollection.AddContentSecurityPolicy(csp =>
{
[...]
csp.AddImgSrc()
.Self()
// Allow loading images from data: links
.Data();
[...]
});
});
}
The oauth2-redirect.html file
Update on 6 July 2022
See the update block at the bottom of this section if you use Swashbuckle v6.0 or greater for an easier solution.
You’re still encouraged to read this section to get the necessary context.
The other HTML file you might be using is the oauth2-redirect.html file, used by default if you decide to implement an authentication flow from swagger-ui.
This can be beneficial as it dramatically eases the discovery of the API endpoints.
At the time of writing, Swashbuckle uses swagger-ui v3.25.0.
If we head over to the swagger-api/swagger-ui repository, we can find the oauth2-redirect.html file.
See https://github.com/swagger-api/swagger-ui/blob/v3.25.0/dist/oauth2-redirect.html.
CSP-wise, we have 2 issues:
- It contains an inline
<script> tag; and
- It contains an inline event handler,
<body onload="run">, which is not supported by Chrome nor the new Edge based on Chromium.
Another point worth noting is that Swashbuckle doesn’t expose a way to override the content of the oauth2-redirect.html file.
The solution we came up with is to hold a slightly modified copy of the oauth2-redirect.html file in our application:
<!-- Original file -->
<body onload="run()">
</body>
<script>
function run () {
[...]
}
</script>
<!-- Modified copy -->
<body>
</body>
<script>
function run () {
[...]
}
document.addEventListener('DOMContentLoaded', function () { run(); });
</script>
By putting this copy in the wwwroot/swagger folder, it’ll then be served by our static files middleware instead of by the Swashbuckle SwaggerUI middleware.
We can then compute the hash of the contents of the <script> tag, and allow it in our content security policy.
However, this is a suboptimal solution for several reasons:
- We need to maintain a modified copy of a dependency file;
- If we update the Swashbuckle NuGet package, it might come with an updated version of swagger-ui, potentially modifying the hash of the inline
<script> tag and breaking our CSP.
We’ve tried to mitigate these from different angles.
The first one is to create a suite of tests that ensure the following statements stay true, minimising the possibility of breaking the app:
- We make sure that the hash we allow in our CSP matches the hash of the contents of the modified copy we keep.
If someone updates or deletes the copy we keep, the test will fail.
Because line endings influence the hash of the contents, we leverage both the
.gitattributes and .editorconfig files to ensure our copy uses LF line endings, consistent with the source file;
- We also make sure that our copy of the file doesn’t “drift” from the one embedded in Swashbuckle’s assembly.
Given we only add a new line at the end of the inline
<script> tag, we can compare them and assert that one is a superset of the other;
- Finally, we have a test to ensure that we still need to keep a copy of the original
oauth2-redirect.html file that moves from using inline event handlers to a solution based on the DOMContentLoaded event.
On that last point.
We opened a pull request on the swagger-api/swagger-ui repository to move away from the inline event handler.
While that PR was merged and the change was released in swagger-ui v3.34.0, it hasn’t flowed down to Swashbuckle.
The hope is that at some point in the future, Swashbuckle will update swagger-ui, we’ll update Swashbuckle, the test will fail, and we’ll be able to remove our modified copy of the file.
🤞 it works out!
Update on 6 July 2022
Swashbuckle, starting with v6.0, is now bundling a version of swagger-ui that contains the change mentioned above in the pull request we opened.
This means that we no longer need to maintain a separate version of the oauth2-redirect.html file.
However, because the file still contains an inline <script> tag, we need to allow its hash in our CSP.
It greatly reduces the complexity of the solution, though, as we now only need to ensure that the hash we allow is the correct one, which we do via an automated test.
Conclusion
In this post, we explored how we can keep a fairly strict content security policy in our app while leveraging the great tools built in the Swashbuckle NuGet package.
Special thanks to:
12 Sep 2020
Introduction
In a previous post, we looked at how we can connect to Azure SQL using Azure Active Directory authentication.
We first discussed a simple way of integrating this with EF Core, using interceptors.
Then, we had a look at a solution to resolve interceptors from the ASP.NET Core dependency injection container.
Unfortunately, that solution was complicated as it involved a lot of plumbing code and was stitching together the application service provider and the internal service provider used by EF Core.
All in all, while functional in my limited testing, I wasn’t confident enough to be using it in production code.
The good news is that I found what I think is a much better solution!
No messing around with the internal service provider, no need to create an extension that is meant to be leveraged by third-party providers.
Just really simple, straightforward code.
Let’s get to it.
How to resolve EF Core interceptors from the dependency injection container
Leveraging the service provider can be beneficial if the interceptor takes dependencies on other services, like a cache for the access tokens or an instance of ILogger.
The solution is actually embarassing given how straightforward it is.
While going through the different overloads of the AddDbContext method, I realised that several of them were accepting a delegate parameter that was given an instance of IServiceProvider.
That’s great news, as it means we can have access to the application service provider while configuring the DbContext options.
To get some context, this is the initial solution we looked at, where we manually create an instance of our interceptor:
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddDbContext<AppDbContext>(options =>
{
options.UseSqlServer(Configuration.GetConnectionString("<connection-string-name>"));
options.AddInterceptors(new AadAuthenticationDbConnectionInterceptor());
});
}
}
public class AadAuthenticationDbConnectionInterceptor : DbConnectionInterceptor
{
public override async Task<InterceptionResult> ConnectionOpeningAsync(
DbConnection connection,
ConnectionEventData eventData,
InterceptionResult result,
CancellationToken cancellationToken)
{
var sqlConnection = (SqlConnection)connection;
//
// Only try to get a token from AAD if
// - We connect to an Azure SQL instance; and
// - The connection doesn't specify a username.
//
var connectionStringBuilder = new SqlConnectionStringBuilder(sqlConnection.ConnectionString);
if (connectionStringBuilder.DataSource.Contains("database.windows.net", StringComparison.OrdinalIgnoreCase) && string.IsNullOrEmpty(connectionStringBuilder.UserID))
{
sqlConnection.AccessToken = await GetAzureSqlAccessToken(cancellationToken);
}
return await base.ConnectionOpeningAsync(connection, eventData, result, cancellationToken);
}
private static async Task<string> GetAzureSqlAccessToken(CancellationToken cancellationToken)
{
// See https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/services-support-managed-identities#azure-sql
var tokenRequestContext = new TokenRequestContext(new[] { "https://database.windows.net//.default" });
var tokenRequestResult = await new DefaultAzureCredential().GetTokenAsync(tokenRequestContext, cancellationToken);
return tokenRequestResult.Token;
}
}
Although this sample interceptor has no dependencies, we can update this sample to resolve it via the service provider:
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
// 1. Register the interceptor in the dependency injection container
services.AddSingleton<AadAuthenticationDbConnectionInterceptor>();
// 2. Use one of the overload of AddDbContext that takes a parameter of type Action<IServiceProvider, DbContextOptionsBuilder>
services.AddDbContext<AppDbContext>((provider, options) =>
{
options.UseSqlServer(Configuration.GetConnectionString("<connection-string-name>"));
// 3. Resolve the interceptor from the service provider
options.AddInterceptors(provider.GetRequiredService<AadAuthenticationDbConnectionInterceptor>());
});
}
}
public class AadAuthenticationDbConnectionInterceptor : DbConnectionInterceptor
{
// Implementation ommitted for brevity
}
As mentioned before, this updated solution is orders of magnitude simpler than the initial one we went through.
I’m much more comfortable with it and I will happily use it in the applications I support.
A note about the lifetime scopes of interceptors and their dependencies
I initially thought that the options associated with a DbContext were built once, meaning that the same instance would be used throughout the lifetime of the application.
However, it turns out that both the DbContext instance and its options are by default registered as scoped services.
In an ASP.NET Core application, it translates to new instances being constructed for each HTTP request.
The implication is that should we need it, our interceptors can be registered as scoped services without causing a captive dependency problem, which is when a service with a “longer” lifetime, like a singleton, takes a dependency on a service with a “shorter” lifetime, like a scoped service.
Naturally, the same principle applies to the dependencies of our interceptors as well.
I’m yet to run into a situation where I need an interceptor to be defined as a scoped service, but it’s good to know it’s a possible option.
The potential need to override both asynchronous and synchronous methods on interceptors
In the previous post mentioned in the introduction and the code snippet above, we define an EF Core interceptor that only overrides the ConnectionOpeningAsync method.
After introducing an AAD authentication interceptor in another project, I found that the ConnectionOpeningAsync method wasn’t always invoked by EF Core.
I thought I had run into a bug, and started working on a minimal repro so I could open an issue on the EF Core GitHub repository.
While doing so, I realised it wasn’t a bug, but a misconception on my part.
When interacting with the DbContext using asynchronous methods like ToListAsync(), CountAsync(), and AnyAsync(), EF Core will invoke the ConnectionOpeningAsync method on the registered interceptor.
However, when using their synchronous counterparts, the synchronous ConnectionOpening method will be called internally.
I didn’t realise this in the first project I introduced interceptors in simply because this code base was consistently using asynchronous methods of the DbContext.
Fortunately, this was a simple fix as the TokenCredential class from the Azure.Core NuGet package, that I leveraged to get an access token to connect to Azure SQL, exposes both a synchronous and asynchronous method to acquire a token.
After making the change, the interceptor looks like below:
public class AadAuthenticationDbConnectionInterceptor : DbConnectionInterceptor
{
// See https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/services-support-managed-identities#azure-sql
private static readonly string[] _azureSqlScopes = new[]
{
"https://database.windows.net//.default"
};
public override async Task<InterceptionResult> ConnectionOpeningAsync(
DbConnection connection,
ConnectionEventData eventData,
InterceptionResult result,
CancellationToken cancellationToken)
{
var sqlConnection = (SqlConnection)connection;
if (ConnectionNeedsAccessToken(sqlConnection))
{
var tokenRequestContext = new TokenRequestContext(_azureSqlScopes);
var token = await new DefaultAzureCredential().GetTokenAsync(tokenRequestContext, cancellationToken);
sqlConnection.AccessToken = token.Token;
}
return await base.ConnectionOpeningAsync(connection, eventData, result, cancellationToken);
}
public override InterceptionResult ConnectionOpening(
DbConnection connection,
ConnectionEventData eventData,
InterceptionResult result)
{
var sqlConnection = (SqlConnection)connection;
if (ConnectionNeedsAccessToken(sqlConnection))
{
var tokenRequestContext = new TokenRequestContext(_azureSqlScopes);
var token = new DefaultAzureCredential().GetToken(tokenRequestContext);
sqlConnection.AccessToken = token.Token;
}
return base.ConnectionOpening(connection, eventData, result);
}
private static bool ConnectionNeedsAccessToken(SqlConnection connection)
{
//
// Only try to get a token from AAD if
// - We connect to an Azure SQL instance; and
// - The connection doesn't specify a username.
//
var connectionStringBuilder = new SqlConnectionStringBuilder(connection.ConnectionString);
return connectionStringBuilder.DataSource.Contains("database.windows.net", StringComparison.OrdinalIgnoreCase) && string.IsNullOrEmpty(connectionStringBuilder.UserID);
}
}
⚠ Update about token caching
As mentioned on Twitter by Joonas Westlin, the DefaultAzureCredential class doesn’t handle token caching, which means that your app could end up requesting a new token for each SQL connection.
As a result, it’s important that applications implement caching to ensure they’re not, in the case of managed identity, calling the token endpoint too often.
Below is a simple but effective solution based on in-memory caching; up to you if you want to implement distributed caching.
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
// 1. Register the in-memory cache
services.AddMemoryCache();
// 2. Register the Azure Identity-based token provider
services.AddSingleton<AzureIdentityAzureSqlTokenProvider>();
// 3. Register a caching decorator using the Scrutor NuGet package
services.Decorate<IAzureSqlTokenProvider, CacheAzureSqlTokenProvider>();
// 4. Finally, register the interceptor
services.AddSingleton<AadAuthenticationDbConnectionInterceptor>();
services.AddDbContext<AppDbContext>((provider, options) =>
{
options.UseSqlServer(Configuration.GetConnectionString("<connection-string-name>"));
options.AddInterceptors(provider.GetRequiredService<AadAuthenticationDbConnectionInterceptor>());
});
}
}
// Simple interface that represents a token acquisition abstraction
public interface IAzureSqlTokenProvider
{
Task<(string AccessToken, DateTimeOffset ExpiresOn)> GetAccessTokenAsync(CancellationToken cancellationToken = default);
(string AccessToken, DateTimeOffset ExpiresOn) GetAccessToken();
}
// Core implementation that performs token acquisition with Azure Identity
public class AzureIdentityAzureSqlTokenProvider : IAzureSqlTokenProvider
{
private static readonly string[] _azureSqlScopes = new[]
{
"https://database.windows.net//.default"
};
public async Task<(string AccessToken, DateTimeOffset ExpiresOn)> GetAccessTokenAsync(CancellationToken cancellationToken = default)
{
var tokenRequestContext = new TokenRequestContext(_azureSqlScopes);
var token = await new DefaultAzureCredential().GetTokenAsync(tokenRequestContext, cancellationToken);
return (token.Token, token.ExpiresOn);
}
public (string AccessToken, DateTimeOffset ExpiresOn) GetAccessToken()
{
var tokenRequestContext = new TokenRequestContext(_azureSqlScopes);
var token = new DefaultAzureCredential().GetToken(tokenRequestContext, default);
return (token.Token, token.ExpiresOn);
}
}
// Decorator that caches tokens in the in-memory cache
public class CacheAzureSqlTokenProvider : IAzureSqlTokenProvider
{
private const string _cacheKey = nameof(CacheAzureSqlTokenProvider);
private readonly IAzureSqlTokenProvider _inner;
private readonly IMemoryCache _cache;
public CacheAzureSqlTokenProvider(
IAzureSqlTokenProvider inner,
IMemoryCache cache)
{
_inner = inner;
_cache = cache;
}
public async Task<(string AccessToken, DateTimeOffset ExpiresOn)> GetAccessTokenAsync(CancellationToken cancellationToken = default)
{
return await _cache.GetOrCreateAsync(_cacheKey, async cacheEntry =>
{
var (token, expiresOn) = await _inner.GetAccessTokenAsync(cancellationToken);
// AAD access tokens have a default lifetime of 1 hour, so we take a small safety margin
cacheEntry.SetAbsoluteExpiration(expiresOn.AddMinutes(-10));
return (token, expiresOn);
});
}
public (string AccessToken, DateTimeOffset ExpiresOn) GetAccessToken()
{
return _cache.GetOrCreate(_cacheKey, cacheEntry =>
{
var (token, expiresOn) = _inner.GetAccessToken();
// AAD access tokens have a default lifetime of 1 hour, so we take a small safety margin
cacheEntry.SetAbsoluteExpiration(expiresOn.AddMinutes(-10));
return (token, expiresOn);
});
}
}
// The interceptor is now using the token provider abstraction
public class AadAuthenticationDbConnectionInterceptor : DbConnectionInterceptor
{
private readonly IAzureSqlTokenProvider _tokenProvider;
public AadAuthenticationDbConnectionInterceptor(IAzureSqlTokenProvider tokenProvider)
{
_tokenProvider = tokenProvider;
}
public override InterceptionResult ConnectionOpening(
DbConnection connection,
ConnectionEventData eventData,
InterceptionResult result)
{
var sqlConnection = (SqlConnection)connection;
if (ConnectionNeedsAccessToken(sqlConnection))
{
var (token, _) = _tokenProvider.GetAccessToken();
sqlConnection.AccessToken = token;
}
return base.ConnectionOpening(connection, eventData, result);
}
public override async Task<InterceptionResult> ConnectionOpeningAsync(
DbConnection connection,
ConnectionEventData eventData,
InterceptionResult result,
CancellationToken cancellationToken = default)
{
var sqlConnection = (SqlConnection)connection;
if (ConnectionNeedsAccessToken(sqlConnection))
{
var (token, _) = await _tokenProvider.GetAccessTokenAsync(cancellationToken);
sqlConnection.AccessToken = token;
}
return await base.ConnectionOpeningAsync(connection, eventData, result, cancellationToken);
}
private static bool ConnectionNeedsAccessToken(SqlConnection connection)
{
//
// Only try to get a token from AAD if
// - We connect to an Azure SQL instance; and
// - The connection doesn't specify a username.
//
var connectionStringBuilder = new SqlConnectionStringBuilder(connection.ConnectionString);
return connectionStringBuilder.DataSource.Contains("database.windows.net", StringComparison.OrdinalIgnoreCase) && string.IsNullOrEmpty(connectionStringBuilder.UserID);
}
}
Conclusion
In this post, we first looked at a much simper and terser option to resolve our EF Core interceptors from the dependency injection container.
We then briefly discussed the lifetime scopes we can use for both our interceptors and their dependencies without running into issues.
Finally, we discovered that in some cases, we need to override both the synchronous and asynchronous methods of our interceptors.
I want to thank my colleague Sam Piper who reviewed this post before publishing.
Thanks ✌
08 Aug 2020
Introduction
Last week, my colleague Stafford Williams was investigating an issue happening on a web application running on Azure App Service.
Application Insights was taking longer than he was happy with to surface the log entries in the Azure portal, so he started using the Log stream feature of App Service.
While log entries were appearing almost instantly there, by default they’re not filtered by category/namespace, so in addition to application logs, he was also getting framework-level logs, coming from MVC for example.
In this post we’ll talk about the ASP.NET Core logging provider for Azure App Service, and more specifically:
- What it does;
- How to enable it;
- How it works; and finally
- How to change its default behaviour.
What it does
The logging provider for Azure App Service integrates with the logging configuration and the Log stream feature of App Service.
In a nutshell, it allows the log entries created by an ASP.NET Core application to be surfaced in Log stream.
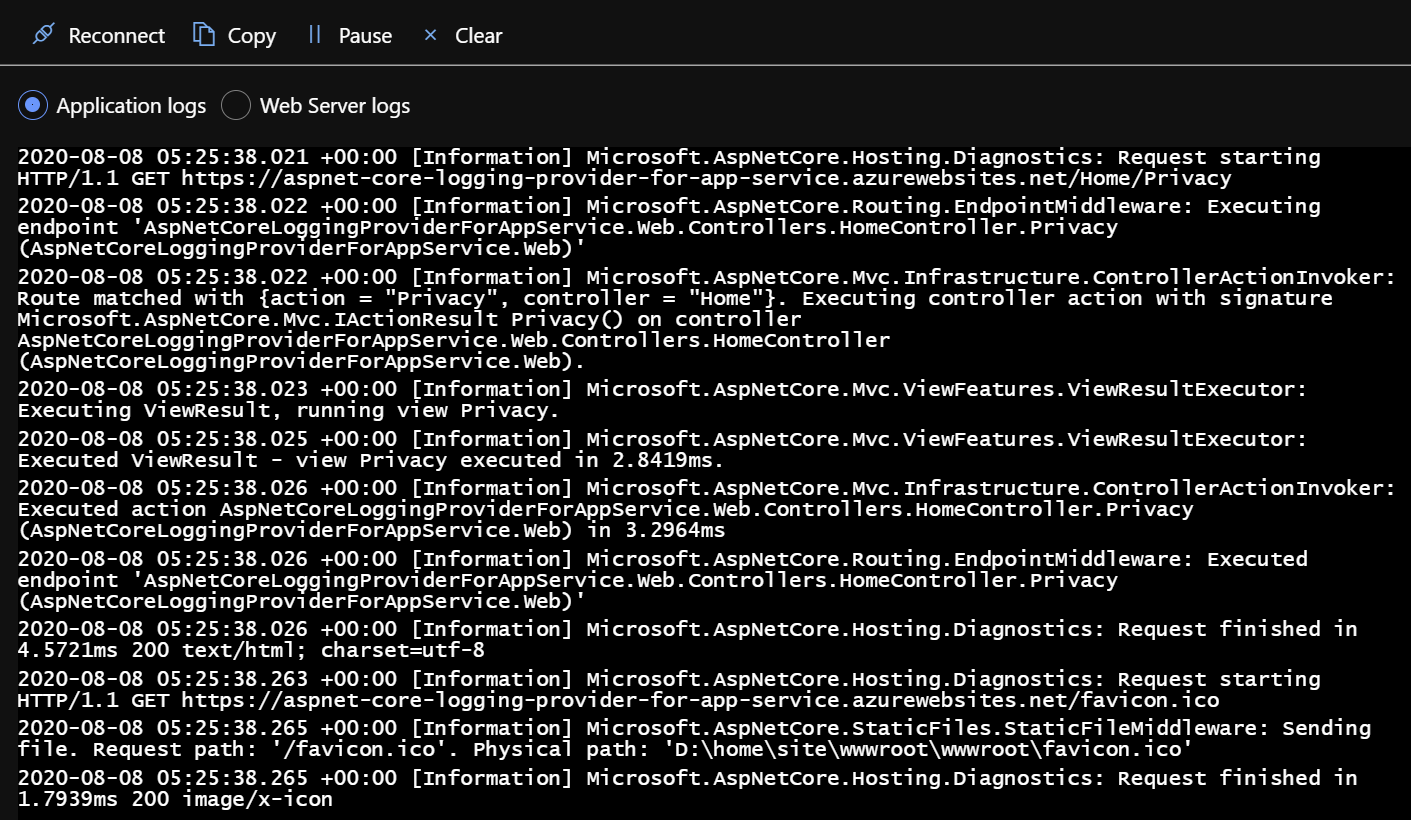 Application log entries surfaced in the Log stream blade of an App Service instance
Application log entries surfaced in the Log stream blade of an App Service instance
Depending on the configuration applied in the App Service logs blade, the provider can write to the App Service file system and/or to a Storage Account, all while respecting the logging level configured for each of them!
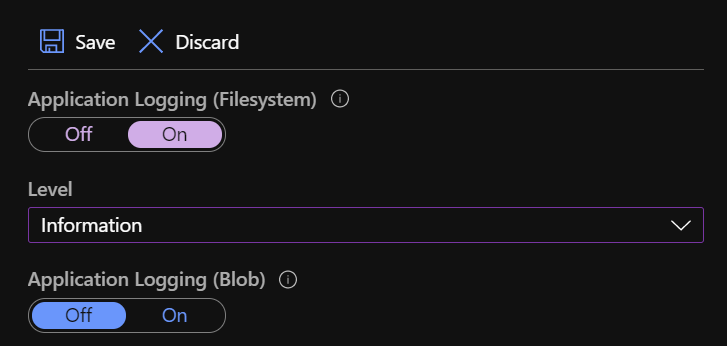 App Service logs blade showing file system and blob storage logging configuration
App Service logs blade showing file system and blob storage logging configuration
Because the Log stream integration is linked to the file system logging configuration, we’ll focus on this one for the rest of the blog post.
Next, let’s see how we can enable this capability in our ASP.NET Core application.
How to enable it
The first way to enable this capability is my personal favourite because it’s explicit; however, it requires code changes.
We need to install the Microsoft.Extensions.Logging.AzureAppServices NuGet package and add the appropriate provider to the logging system.
It really is that simple:
// Program.cs
+using Microsoft.Extensions.Logging;
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
+ .ConfigureLogging(builder => builder.AddAzureWebAppDiagnostics())
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
The other option, if we’re in a situation where a code change is not possible for example, is to install the ASP.NET Core Logging Integration App Service extension, which we can do by navigating to the Extensions blade of our App Service.
I also found that the Azure portal offers to install this extension when I went to the App Service logs blade.
My guess is that the Stack property in Configuration > General settings must be set to .NET Core for that option to appear.
 The banner we can click to install the ASP.NET Core Logging Integration extension
The banner we can click to install the ASP.NET Core Logging Integration extension
Let’s now focus on the way this provider works.
How it works
I learned lots of things while looking up the implementation of that provider, which as always is open-source on GitHub. This link — and the following ones in this post — specifically points to the release/3.1 branch instead of master because the latter has seen a lot of changes in preparation for .NET 5, the most notable being a lot of code moving from the dotnet/extensions repo to the dotnet/runtime one.
The first observation is that this provider is only enabled when the app runs on App Service, which is detected through a number of well-known environment variables defined in App Service.
We’ll see later how we can take advantage of this to enable it when running the app locally.
The next interesting bit is discovering that the App Service file logger writes log entries to files in the %HOME%\LogFiles\Application directory, as seen in the code.
This explains why those entries show up in the Log stream feature of App Service, as the official documentation points out that:
[…] information written to files ending in .txt, .log, or .htm that are stored in the /LogFiles directory (d:/home/logfiles) is streamed by App Service.
Another finding is that the settings configured in the App Service logs blade are persisted in a JSON file on the App Service file system, more specifically in the %HOME%\site\diagnostics\settings.json file for a Windows App Service, which is loaded in a separate configuration object.
It’s worth noting that reload is enabled, indicating that logging settings can be updated and picked up by the app without requiring a restart, which is definitely a good thing.
Here’s what the structure of this file looks like:
{
// File system settings
"AzureDriveEnabled": true,
"AzureDriveTraceLevel": "Information",
// Blob storage settings
"AzureBlobEnabled": false,
"AzureBlobTraceLevel": "Error",
// I suppose those are Table storage settings, but
// neither the App Service logs blade nor the App Service logging provider
// seem to set or use them
"AzureTableEnabled": false,
"AzureTableTraceLevel": "Error"
}
The AzureDriveEnabled property drives whether log entries are written to the file system, while the AzureDriveTraceLevel one controls the minimum level for the entries to be processed by the provider.
Let’s dig deeper on how log entries are filtered based on their level.
Segue into the ASP.NET Core logging system
The logging stack in ASP.NET Core has built-in support for filters, each of them optionally defining:
- Which logging provider it applies to;
- Which category or namespace it matches; and finally
- The minimum level for log entries to satisfy the filter.
The most common way to define filters is through the Logging section of the appsettings.json file, as documented and explained in the official documentation on docs.microsoft.com.
However, filters can also be defined in code, which is the method used by the App Service logger provider.
After loading the logging configuration from the JSON file, a new filter is added to the global configuration with the following settings:
- It only applies to the
FileLoggerProvider, which is the one responsible to writing log entries to the file system;
- No category or namespace is specified, meaning all log entries will be matched; and
- A minimum level is configured, based on the value of the
AzureDriveTraceLevel property.
See below an extract of the code, which may help put the pieces together:
public static class AzureAppServicesLoggerFactoryExtensions
{
internal static ILoggingBuilder AddAzureWebAppDiagnostics(this ILoggingBuilder builder, IWebAppContext context)
{
[...]
// This reads the `%HOME%\site\diagnostics\settings.json` JSON file mentioned earlier
var config = SiteConfigurationProvider.GetAzureLoggingConfiguration(context);
[...]
services.AddSingleton<IConfigureOptions<LoggerFilterOptions>>(CreateFileFilterConfigureOptions(config));
[...]
}
private static ConfigurationBasedLevelSwitcher CreateFileFilterConfigureOptions(IConfiguration config)
{
return new ConfigurationBasedLevelSwitcher(
configuration: config,
provider: typeof(FileLoggerProvider),
levelKey: "AzureDriveTraceLevel");
}
}
internal class ConfigurationBasedLevelSwitcher : IConfigureOptions<LoggerFilterOptions>
{
private readonly IConfiguration _configuration;
private readonly Type _provider;
private readonly string _levelKey;
public ConfigurationBasedLevelSwitcher(IConfiguration configuration, Type provider, string levelKey)
{
_configuration = configuration;
_provider = provider;
_levelKey = levelKey;
}
public void Configure(LoggerFilterOptions options)
{
options.Rules.Add(new LoggerFilterRule(_provider.FullName, null, GetLogLevel(), null));
}
private LogLevel GetLogLevel()
{
// Implementation omitted for brevity
// Mapping between the log level defined in App Service JSON file (_levelKey) to a LogLevel value
}
}
We now know that the App Service provider takes advantage of the built-in filtering capability of the logging system to limit which entries are written to the file system, making sure that the configured minimum log level is respected.
How the options system allows for a dynamic rule
We’ve established earlier in the post that changes to the logging configuration in App Service are picked up by the application without needing to restart the application.
However, the code shown above doesn’t exhibit any dynamic capability: the filtering rule is added to the configuration once, with whatever minimum level is configured when that specific code is executed.
How can the provider then dynamically adjust to logging configuration changes?
The answer lies in the fact that the options system in ASP.NET Core supports change notifications and reloadable configuration through the IOptionsMonitor<T> interface, as mentioned in the official documentation.
We can register change token sources that will be listened to by the default implementation OptionsMonitor<T>, and every time a change notification is fired, the specific options value will be created from scratch.
See this excerpt of code taken from GitHub:
public OptionsMonitor(
// The service responsible for building the options values
IOptionsFactory<TOptions> factory,
// The sources of change tokens that are listened to
IEnumerable<IOptionsChangeTokenSource<TOptions>> sources,
// The service that caches options values until a change is detected
IOptionsMonitorCache<TOptions> cache)
{
_factory = factory;
_sources = sources;
_cache = cache;
foreach (var source in _sources)
{
// 1. Subscribe to changes from all token sources, and invoke `InvokeChanged` whenever one notifies of a change.
var registration = ChangeToken.OnChange(
() => source.GetChangeToken(),
(name) => InvokeChanged(name),
source.Name);
_registrations.Add(registration);
}
}
private void InvokeChanged(string name)
{
// 2. Remove the cached options value and call `Get` to build a new one.
name = name ?? Options.DefaultName;
_cache.TryRemove(name);
var options = Get(name);
// 4. Now that we've built a new instance, let subscribers know about it.
if (_onChange != null)
{
_onChange.Invoke(options, name);
}
}
public virtual TOptions Get(string name)
{
// 3. When this is called from `InvokeChanged`, the cached value has just been removed,
// so the options factory is used to build a new options value.
name = name ?? Options.DefaultName;
return _cache.GetOrAdd(name, () => _factory.Create(name));
}
Do you remember how we noticed earlier that the App Service logging provider loaded the %HOME%\site\diagnostics\settings.json file into a configuration object and changes to the file could be picked up by enabling the reload capability?
The options system provides an adapter for the configuration stack so that a change in configuration can also be interpreted as an options change notification, and the logging provider for App Service makes use of it:
public static class AzureAppServicesLoggerFactoryExtensions
{
internal static ILoggingBuilder AddAzureWebAppDiagnostics(this ILoggingBuilder builder, IWebAppContext context)
{
[...]
// This reads the `%HOME%\site\diagnostics\settings.json` JSON file mentioned earlier
var config = SiteConfigurationProvider.GetAzureLoggingConfiguration(context);
[...]
services.AddSingleton<IOptionsChangeTokenSource<LoggerFilterOptions>>(new ConfigurationChangeTokenSource<LoggerFilterOptions>(config));
[...]
}
}
So far, we’ve established that a configuration change can trigger an options change notification, which will cause the targetted options value to be recreated.
How options values are built
Now, how does the options factory build up a new value?
It uses the several actions that have been registered to configure the value.
There are 3 types of actions that can be registered:
IConfigureOptions<T> to configure the default options value;IConfigureNamedOptions<T> to configure an options value with a specific name; andIPostConfigureOptions<T> to ensure a configuration step happens after the previous two we mentioned.
Here’s what the OptionsFactory<T> class implementation looks like, although you can always look at it on GitHub directly:
public OptionsFactory(
// The configuration actions.
IEnumerable<IConfigureOptions<TOptions>> setups,
// The post-configuration actions.
IEnumerable<IPostConfigureOptions<TOptions>> postConfigures,
// Out of the scope of this post, but one can register validation steps for an options value as well.
IEnumerable<IValidateOptions<TOptions>> validations)
{
_setups = setups;
_postConfigures = postConfigures;
_validations = validations;
}
public TOptions Create(string name)
{
// 1. New up a default instance of our options.
var options = new TOptions();
// 2. Run all configuration actions on the created instance.
foreach (var setup in _setups)
{
if (setup is IConfigureNamedOptions<TOptions> namedSetup)
{
namedSetup.Configure(name, options);
}
else if (name == Options.DefaultName)
{
setup.Configure(options);
}
}
// 3. Finally, run all post-configuration steps.
foreach (var post in _postConfigures)
{
post.PostConfigure(name, options);
}
// 4. Omitted for brevity is the execution of the validation steps.
[...]
// 5. Return the configured options value.
return options;
}
How the logging system is made aware of options changes
The logging system supports changes to the logging options by internally using an instance of IOptionsMonitor<LoggerFilterOptions> and subscribing to its changes, which when fired will trigger a reevaluation of which filters need to be applied.
Without going into the filter selection logic, this piece of code from the LoggerFactory class reveals how it subscribes to changes:
public LoggerFactory(
IEnumerable<ILoggerProvider> providers,
IOptionsMonitor<LoggerFilterOptions> filterOption)
{
foreach (var provider in providers)
{
AddProviderRegistration(provider, dispose: false);
}
// 1. Subscribe to options changes, and trigger a refresh of filters when one is triggered.
_changeTokenRegistration = filterOption.OnChange(RefreshFilters);
// 2. Set up filters according to the initial value of logging options.
RefreshFilters(filterOption.CurrentValue);
}
private void RefreshFilters(LoggerFilterOptions filterOptions)
{
// Implementation omitted.
// Refreshes filters applied to existing logging providers.
}
Putting it all together
We now have all the pieces to understand how it all works, as we have established the following sequence of events:
- In the Azure portal or through the Azure CLI, we make a change to the logging configuration on our App Service instance;
- The new configuration settings are persisted in a JSON file on the App Service file system;
- The configuration system loads up the new settings from the updated file and triggers a change notification;
- This configuration change is also picked up by the options system through the configuration-to-options adapter, which triggers a rebuild of the
LoggerFilterOptions value;
- The options system executes all the registered configuration actions for
LoggerFilterOptions;
- One of these configuration actions, as seen earlier, adds a logging filtering rule for the file system logging provider, using the new minimum log level option configured in step 1;
- The options system notifies change subscribers about the new constructed value;
- The logging stack, which is a subscriber of changes to logging options, triggers a refresh of its filters; and finally
- The new filter that targets the App Service file system logging provider ensures only entries with a matching log level get written to disk.
Phew.
We made it 🎉!
Or did we?
How to customise it
Let’s remember what my mate Stafford was unhappy about: his application log entries were shown in Log stream, but because the log filter didn’t specify a namespace or category, the output was cluttered with entries coming from MVC, making the troubleshooting easier.
The good news is that thanks to our understanding of how it all works, we can help Stafford!
The code in this sample is available on GitHub on my mderriey/aspnet-core-logging-provider-for-app-service repository.
The solution I came up with is to add a post-configuration step for logging options, and replace the default filtering rule added by the App Service file system logging provider.
The two new rules we’re adding still only apply to this specific logging provider, but have different category and log level properties:
- The first one specifies no category and uses a fixed minimum log level of Error; and
- Another rule that uses the minimum log level defined in the App Service logging configuration, but specifies a category that corresponds to the root namespace of our application.
Only one filtering rule is applied for a single logging provider, and the selection logic will favour one that has a matching category, even if the match is only partial.
The result is that loggers created by internal ASP.NET Core code will be applied the first rule, while the ones created for our custom types will trigger the selection of the second one.
// Startup.cs
public void ConfigureServices(IServiceCollection services)
{
services.PostConfigure<LoggerFilterOptions>(options =>
{
var originalRule = options.Rules.FirstOrDefault(x => x.ProviderName == typeof(FileLoggerProvider).FullName);
if (originalRule != null)
{
options.Rules.Remove(originalRule);
options.AddFilter<FileLoggerProvider>(category: null, level: LogLevel.Error);
options.AddFilter<FileLoggerProvider>(category: "AspNetCoreLoggingProviderForAppService", level: originalRule.LogLevel.Value);
}
});
}
Making sure it works as expected
We can run an MVC app locally to confirm that the solution works.
As discussed earlier, the App Service logging provider is only enabled when the HOME and WEBSITE_SITE_NAME environment variables are set, as they are usually only present when the app runs in App Service.
We can simulate running in that environment by settings these in the lauchSettings.json file.
I’m using IIS Express, so I added them to the appropriate profile, but you can add them to the other if you run the app on Linux or through dotnet run:
{
"iisSettings": {
"windowsAuthentication": false,
"anonymousAuthentication": true,
"iisExpress": {
"applicationUrl": "https://localhost:44391",
"sslPort": 44391
}
},
"profiles": {
"IIS Express": {
"commandName": "IISExpress",
"launchBrowser": true,
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Development",
+ "HOME": "<replace-with-the-absolute-path-to-the-home-directory-of-the-git-repository>",
+ "WEBSITE_SITE_NAME": "AspNetCoreLoggingProviderForAppService.Web"
}
},
"AspNetCoreLoggingProviderForAppService.Web": {
"commandName": "Project",
"launchBrowser": true,
"applicationUrl": "https://localhost:44391",
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Development"
}
}
}
}
The other configuration that is required is the JSON file from which the logging configuration is loaded from.
We’ve seen that this file is loaded from %HOME%\site\diagnostics\settings.json, so let’s create it in the appropriate location.
The example below enabled logging to the file system, with a minimum log level of Information:
{
"AzureDriveEnabled": true,
"AzureDriveTraceLevel": "Information"
}
The final bit before we can run the application is to generate some log entries:
public class HomeController : Controller
{
private readonly ILogger<HomeController> _logger;
public HomeController(ILogger<HomeController> logger)
{
// Category is the fully-qualified type name of the type we request the ILogger for.
// In this case, it's AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController.
_logger = logger;
}
public IActionResult Index()
{
EmitLogEntries(nameof(Index));
return View();
}
private void EmitLogEntries(string viewName)
{
const string messageTemplate = "Emitting log entry with level {Level} while executing view {View}";
_logger.LogTrace(messageTemplate, LogLevel.Trace, viewName);
_logger.LogDebug(messageTemplate, LogLevel.Debug, viewName);
_logger.LogInformation(messageTemplate, LogLevel.Information, viewName);
_logger.LogError(messageTemplate, LogLevel.Error, viewName);
_logger.LogCritical(messageTemplate, LogLevel.Critical, viewName);
}
}
If we run the app without our post-configuration action on the logging options and hit the home page, we can see that a text file has been created at %HOME%\LogFiles\Application\diagnostics-yyyyMMdd.txt, which certifies our emulation of running in App Service is correctly picked up.
Looking at the content of the file, we can see many entries, and they confirm two things.
First, all entries have a log level of Information or higher, so the AzureDriveTraceLevel property is respected.
We can also notice many entries that originate from framework-level code:
2020-08-09 15:59:09.860 +10:00 [Information] Microsoft.AspNetCore.DataProtection.KeyManagement.XmlKeyManager: User profile is available. Using 'C:\Users\me\AppData\Local\ASP.NET\DataProtection-Keys' as key repository and Windows DPAPI to encrypt keys at rest.
2020-08-09 15:59:09.946 +10:00 [Information] Microsoft.Hosting.Lifetime: Application started. Press Ctrl+C to shut down.
2020-08-09 15:59:09.946 +10:00 [Information] Microsoft.Hosting.Lifetime: Hosting environment: Development
2020-08-09 15:59:09.946 +10:00 [Information] Microsoft.Hosting.Lifetime: Content root path: C:\Users\me\dev\aspnet-core-logging-provider-for-app-service\src\AspNetCoreLoggingProviderForAppService.Web
2020-08-09 15:59:09.955 +10:00 [Information] Microsoft.AspNetCore.Hosting.Diagnostics: Request starting HTTP/2.0 GET https://localhost:44391/
2020-08-09 15:59:09.969 +10:00 [Information] Microsoft.AspNetCore.Routing.EndpointMiddleware: Executing endpoint 'AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController.Index (AspNetCoreLoggingProviderForAppService.Web)'
2020-08-09 15:59:09.991 +10:00 [Information] Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker: Route matched with {action = "Index", controller = "Home"}. Executing controller action with signature Microsoft.AspNetCore.Mvc.IActionResult Index() on controller AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController (AspNetCoreLoggingProviderForAppService.Web).
2020-08-09 15:59:09.993 +10:00 [Information] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Information while executing view Index
2020-08-09 15:59:09.997 +10:00 [Error] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Error while executing view Index
2020-08-09 15:59:09.997 +10:00 [Critical] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Critical while executing view Index
2020-08-09 15:59:10.010 +10:00 [Information] Microsoft.AspNetCore.Mvc.ViewFeatures.ViewResultExecutor: Executing ViewResult, running view Index.
2020-08-09 15:59:10.066 +10:00 [Information] Microsoft.AspNetCore.Mvc.ViewFeatures.ViewResultExecutor: Executed ViewResult - view Index executed in 60.3482ms.
2020-08-09 15:59:10.067 +10:00 [Information] Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker: Executed action AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController.Index (AspNetCoreLoggingProviderForAppService.Web) in 75.7041ms
2020-08-09 15:59:10.067 +10:00 [Information] Microsoft.AspNetCore.Routing.EndpointMiddleware: Executed endpoint 'AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController.Index (AspNetCoreLoggingProviderForAppService.Web)'
2020-08-09 15:59:10.069 +10:00 [Information] Microsoft.AspNetCore.Hosting.Diagnostics: Request finished in 114.2617ms 200 text/html; charset=utf-8
Let’s now add back our post-configuration action, and run the app again.
Success 🎉!
All the framework-level entries have disappeared, because they had a log level lower than Error.
However, our custom log entries are still written to the file as expected:
2020-08-09 16:09:26.299 +10:00 [Information] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Information while executing view Index
2020-08-09 16:09:26.309 +10:00 [Error] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Error while executing view Index
2020-08-09 16:09:26.309 +10:00 [Critical] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Critical while executing view Index
Without stopping the app, let’s modify the the %HOME%\site\diagnostics\settings.json file, update the AzureDriveTraceLevel to Verbose, and refresh the page:
2020-08-09 16:11:08.434 +10:00 [Trace] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Trace while executing view Index
2020-08-09 16:11:08.434 +10:00 [Debug] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Debug while executing view Index
2020-08-09 16:11:08.434 +10:00 [Information] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Information while executing view Index
2020-08-09 16:11:08.435 +10:00 [Error] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Error while executing view Index
2020-08-09 16:11:08.435 +10:00 [Critical] AspNetCoreLoggingProviderForAppService.Web.Controllers.HomeController: Emitting log entry with level Critical while executing view Index
Conclusion
First, thank you for making it all the way down here.
This is easily the longest post I’ve written, and I sincerely appreciate you read all of it.
I also want to thank Stafford for reviewing this post before publishing.
In this post, we first discussed what the ASP.NET Core logging provider for App Service is, what it does, and how to enable it in your application.
We then analysed its implementation, and discovered it uses built-in capabilities of many foundational parts of ASP.NET Core, such as the configuration and options systems, as well as the primitives used for change notifications.
After putting all the pieces together, we came up with a solution to customise which log entries are written to disk and output by App Service Log stream, and found a way to validate that it is working locally.
If you have any questions or comments, please let me know on Twitter!
Cheers 🙇♂️
